Synergies Between Affordance and Geometry: 6-DoF Grasp Detection via Implicit Representations
Intro
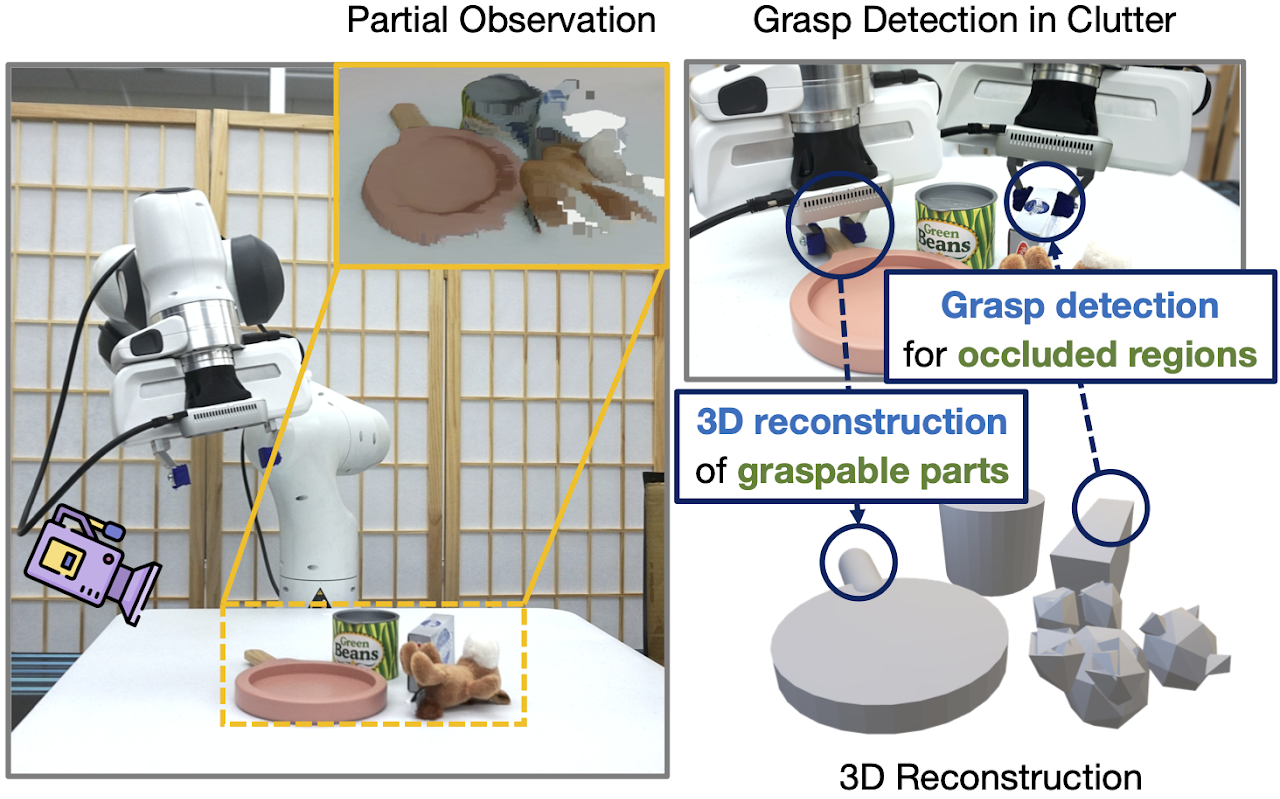
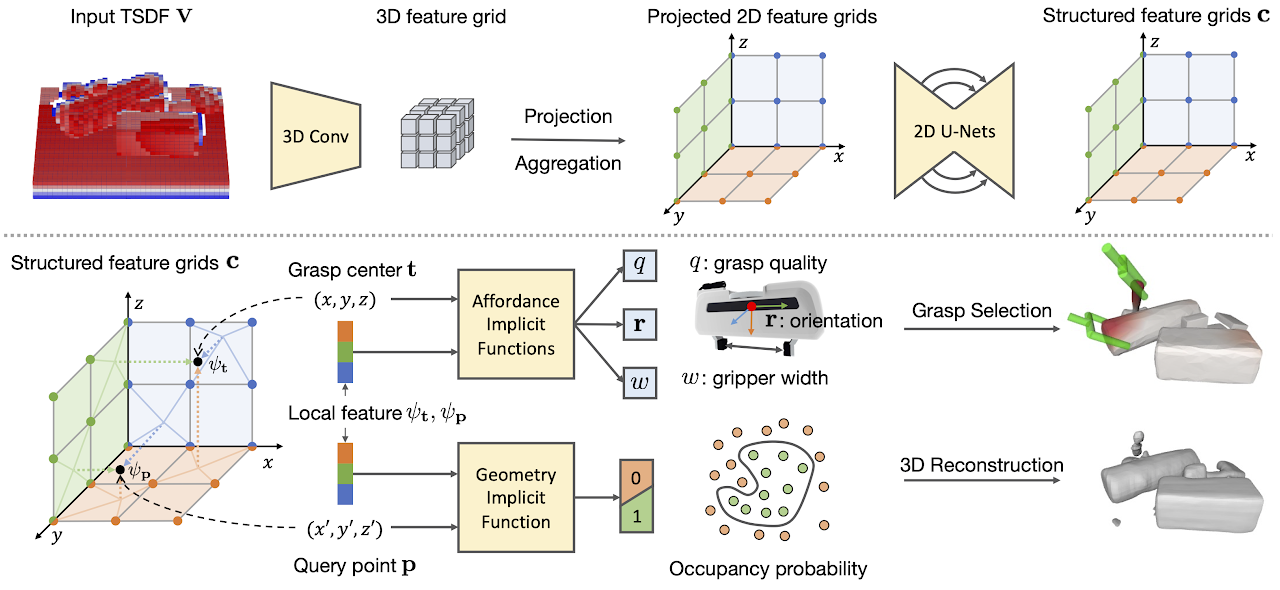
Grasp detection in clutter requires the robot to reason about the 3D scene from incomplete and noisy perception. In this work, we draw insight that 3D reconstruction and grasp learning are two intimately connected tasks, both of which require a fine-grained understanding of local geometry details. We thus propose to utilize the synergies between grasp affordance and 3D reconstruction through multi-task learning of a shared representation. Our model takes advantage of deep implicit functions, a continuous and memory-efficient representation, to enable differentiable training of both tasks. We train the model on self-supervised grasp trials data in simulation. Evaluation is conducted on a clutter removal task, where the robot clears cluttered objects by grasping them one at a time. The experimental results in simulation and on the real robot have demonstrated that the use of implicit neural representations and joint learning of grasp affordance and 3D reconstruction have led to state-of-the-art grasping results. Our method outperforms baselines by over 10% in terms of grasp success rate.
Results
Real-robot grasping in packed.mp4 and pile.mp4.
Funding Support
This work has been supported by NSF CNS1955523 and the MLL Research Award from the Machine Learning Laboratory at UT-Austin.
Associated photos with description
Acknowledgments
We would like to thank Zhiyao Bao for efforts on affordance visualization.
References
@misc{jiang2021synergies,
title={Synergies Between Affordance and Geometry: 6-DoF Grasp Detection via Implicit Representations},
author={Zhenyu Jiang and Yifeng Zhu and Maxwell Svetlik and Kuan Fang and Yuke Zhu},
year={2021},
eprint={2104.01542},
archivePrefix={arXiv},
primaryClass={cs.RO}
}