STEADY: Simultaneous State Estimation and Dynamics Learning from Indirect Observations
Introduction
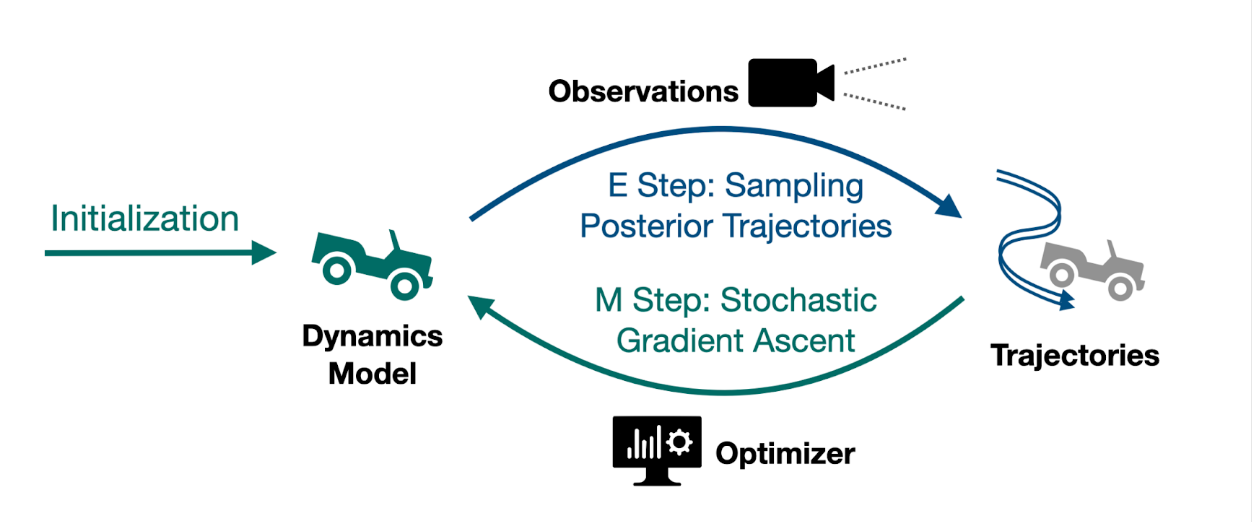
Accurate kinodynamic models play a crucial role in many robotics applications such as off-road navigation and high-speed driving. Many state-of-the-art approaches in learning stochastic kinodynamic models, however, require precise measurements of robot states as labeled input/output examples, which can be hard to obtain in outdoor settings due to limited sensor capabilities and the absence of ground truth. In this work, we propose a new technique for learning neural stochastic kinodynamic models from noisy and indirect observations by performing simultaneous state estimation and dynamics learning. The proposed technique iteratively improves the kinodynamic model in an expectation-maximization loop, where the E Step samples posterior state trajectories using particle filtering, and the M Step updates the dynamics to be more consistent with the sampled trajectories via stochastic gradient ascent. We evaluate our approach on both simulation and real-world benchmarks and compare it with several baseline techniques. Our approach not only achieves significantly higher accuracy but is also more robust to observation noise, thereby showing promise for boosting the performance of many other robotics applications
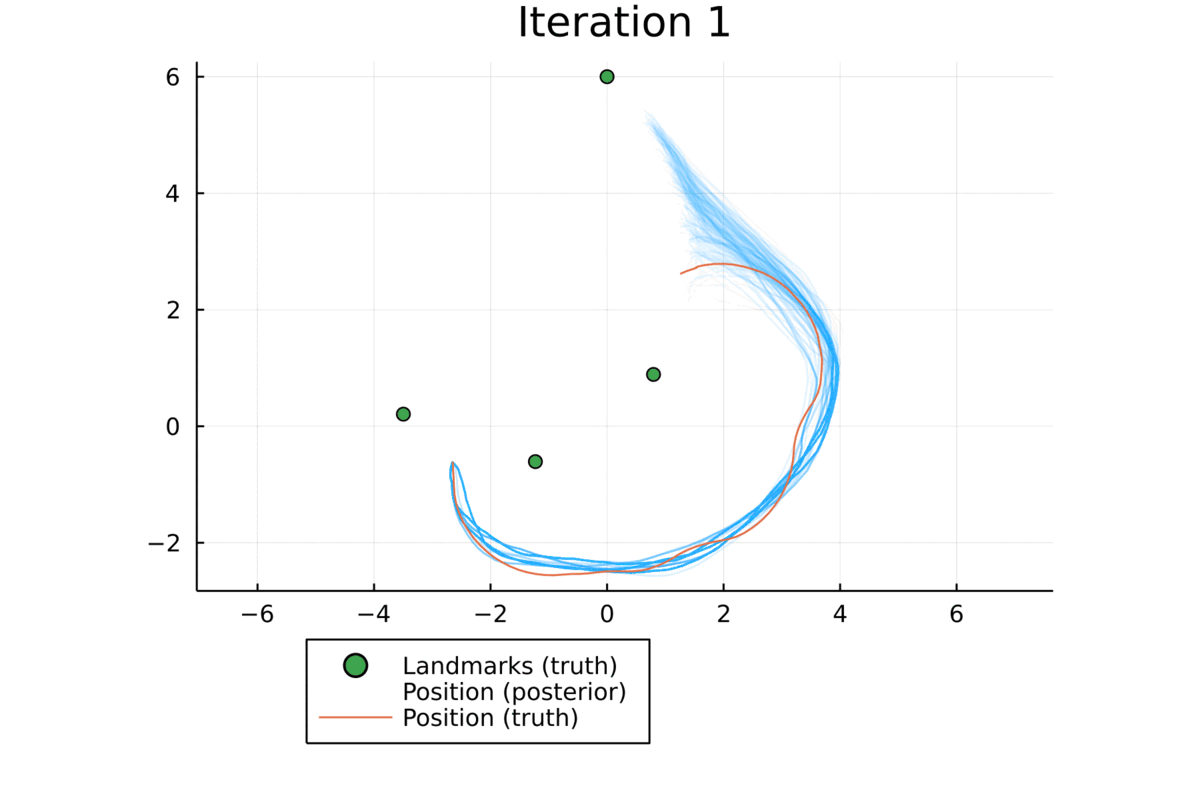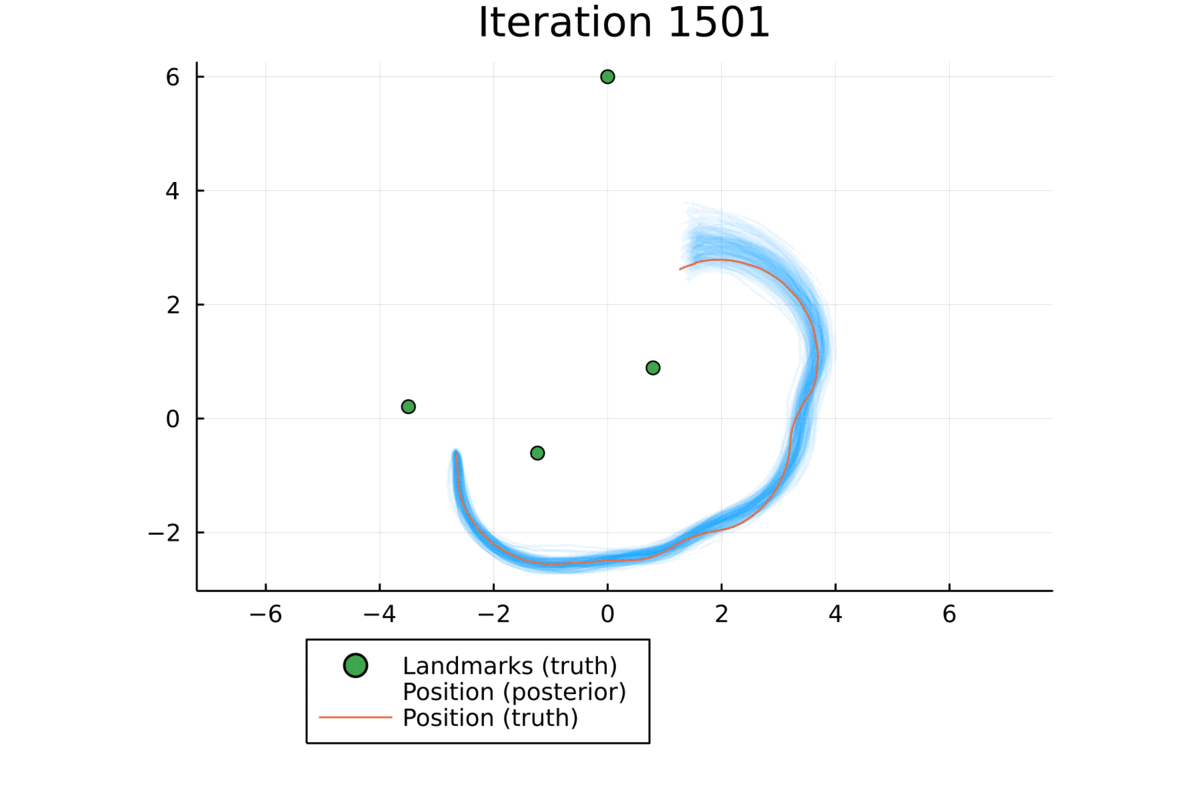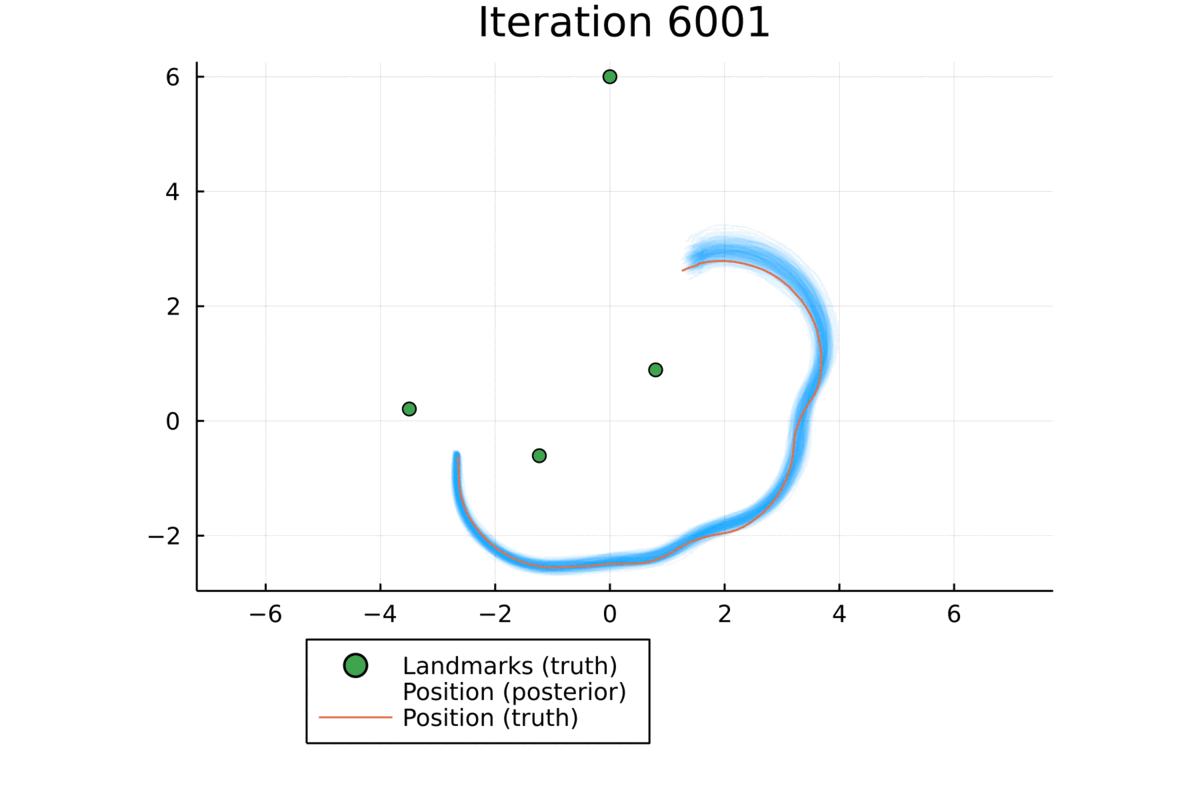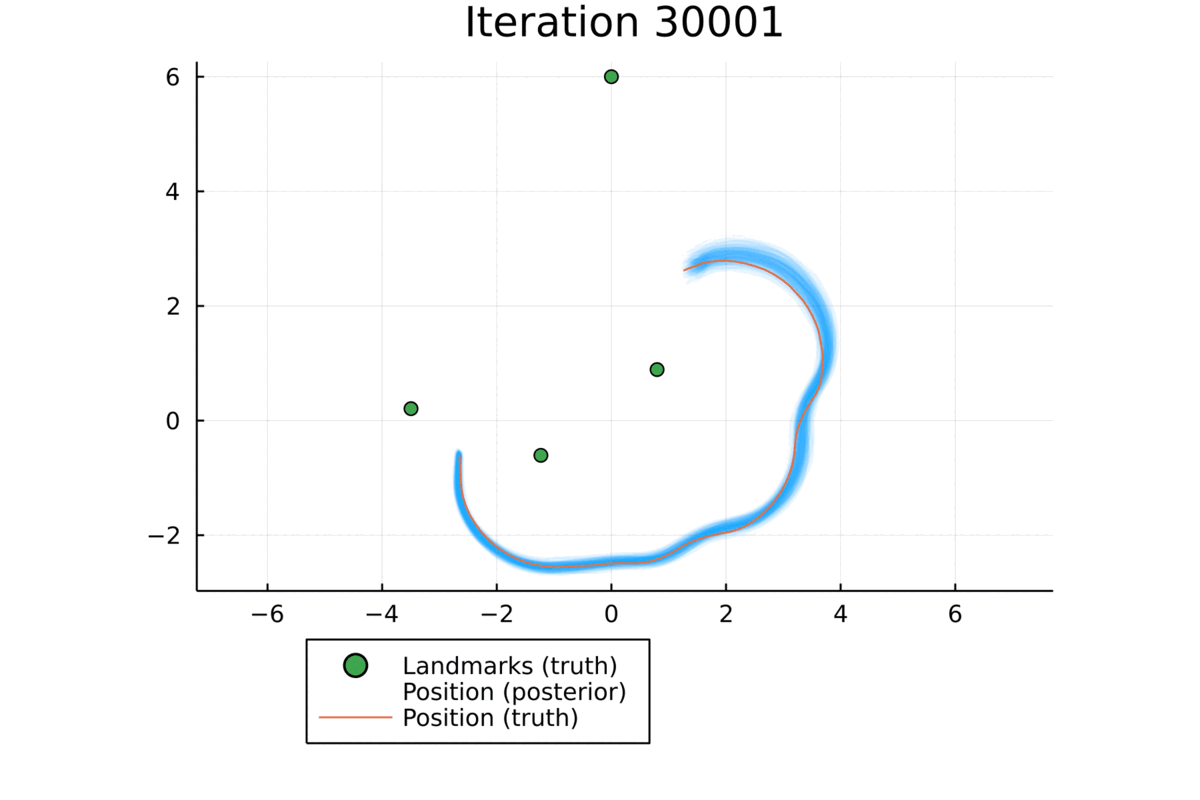
Qualitative Results
Below we visually compare the posterior velocities estimated by our approach (left) with a baseline learning approach (right) that performs state estimation and dynamics learning in two stages. The baseline approach was unable to capture the nuances of the lateral motion of an autonomous car due to the modeling flaw in the dynamical model it used to perform the state estimation, whereas our approach was able to overcome this by improving the dynamical model and state estimation iteratively.
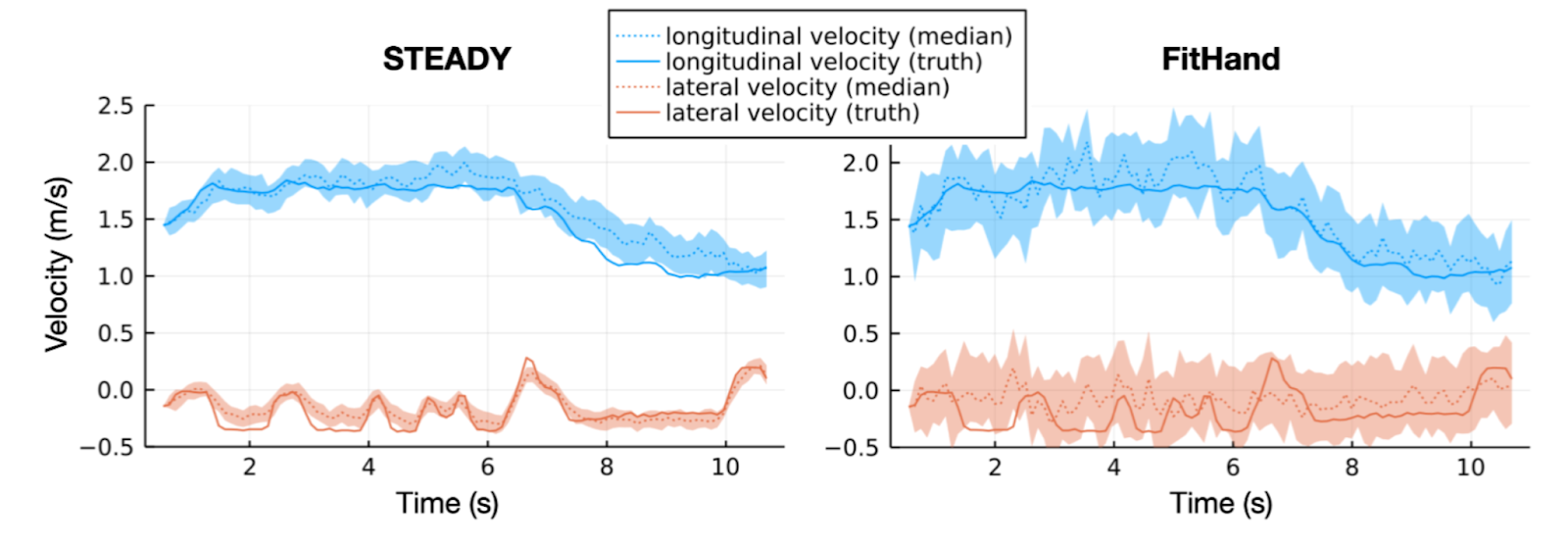
Quantitative Results
We compare the forward state prediction performance of STEADY with 5 other learning approaches. From the table we see that STEADY consistently outperforms all other baselines on all datasets and in many cases achieves a performance level that is very similar to FitTruth (which directly learns from ground truth states and serves as an upper bound).