Learning Under Ambiguity with Different Amounts of Annotation

Training NLP systems typically assumes access to annotated data that has a single human label per example. However, this is problematic given imperfect labeling from annotators and the inherent ambiguity of language.
In this work, we explore new annotation distribution schemes, assigning multiple human annotators per example for a small subset of training examples. For a fair comparison, the total number of annotations remains the same, and we bring such multi-label examples at the cost of annotating fewer examples. This simple redistribution of the annotation budget significantly improves how well the model output matches label distribution of human annotators, as well as classification accuracy on majority labels in two NLP tasks, natural language inference, and fine-grained entity typing.
Further, we extend a MixUp data augmentation framework that can learn from training examples with different amounts of annotation (with zero, one, or multiple labels). This algorithm efficiently combines signals from uneven training data and brings additional gains in low annotation budget and cross-domain settings.
In many NLP tasks, some examples are interpreted differently by different people (high entropy human label distributions), while other examples remain relatively unambiguous to most people (low entropy human label distribution). Ideally, model output should shows similar ambiguity – certain on clear examples, less so on ambiguous examples. The figure shows the empirical example count distribution over entropy bins on the popular natural language inference (NLI) dataset (three-way classification task). The left top plot (a) shows the annotated human label entropy. The right top plot (b) shows the baseline model (trained with single annotated data) output entropy distribution. The baseline model outputs are overly confident, assigning a larger percentage of examples to have low entropy. Training with multi-label data, our method (c) recovers the example entropy distribution similar to the human label distribution.
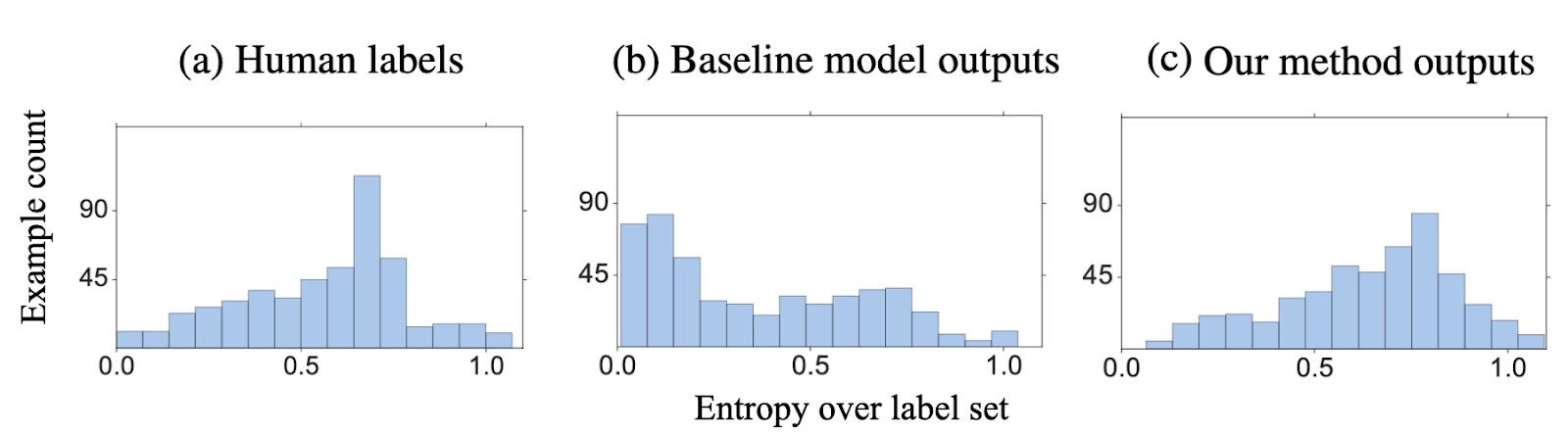
Our work demonstrates the benefits of introducing a small amount of multi-label examples at the cost of annotating fewer examples. Here we retrospectively study with existing data to question original annotation collection designs. Exploring reinforcement learning or active learning to predict an optimal distribution of annotation budget will be an exciting avenue for future work.
References:
Shujian Zhang, Chengyue Gong, and Eunsol Choi. 2021.
Learning with Different Amounts of Annotation: From Zero to Many Labels. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7620–7632, Online and Punta Cana, Dominican Republic. Association for Computational Linguistics.