Learning from Hallucination (LfH)

Intro
While classical approaches to autonomous robot navigation currently enable operation in certain environments, they break down in tightly constrained spaces, e.g., where the robot needs to engage in agile maneuvers to squeeze between obstacles. Classical motion planners require increased computation in those highly constrained spaces, e.g., sampling-based planners need more samples and optimization-based planners need more optimization iterations. While recent machine learning techniques have the potential to address this shortcoming, one conundrum of learning safe motion planners is that in order to produce safe motions in obstacle occupied spaces, robots need to first learn in those dangerous spaces without the ability of planning safe motions. Therefore, they either require a good expert demonstration or exploration based on trial and error, both of which become costly in highly constrained and therefore dangerous spaces. In Learning from Hallucination (LfH), we address this problem by allowing the robot to safely explore in a completely open environment without any obstacles, and then creating the obstacle configurations onto the robot perception, where the motions executed in the open training environment are optimal. In particular, we propose three hallucination methods: (1) hallucinating the most constrained obstacle set (LfH), (2) hallucinating the minimal obstacle set and then sample in addition to it (HLSD), and (3) learning a hallucination function in a self-supervised manner (LfLH). These hallucination methods can generate a large amount of training data from random exploration in open spaces without the need of expert demonstration or trial and error, from which agile motion planners can be efficiently learned to address realistic highly constrained spaces. Learning from Hallucination also allows mobile robots to improve navigation performance with increased real-world experiences in a self-supervised manner. Our experiment results show that motion planners learned from hallucination can enable agile navigation in highly constrained environments.
Learning from Hallucination (LfH)
Given motion plans collected through random exploration in open space, LfH uses a hallucination function to hallucinate the most constrained obstacle configuration, which makes the collected motion plan optimal. We then learn a mapping from the most constrained obstacle sets to the optimal motion plans collected in open space using a small neural network.
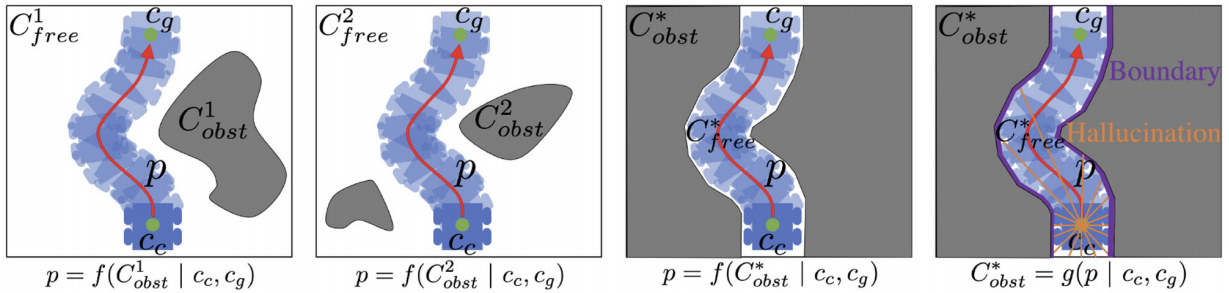
During deployment, the robot seeks help from a coarse global path generated by a global planner and creates runtime hallucination. This matches the realistic obstacle configurations during deployment with the most constrained obstacle sets during training. To address uncertainty, we add Gaussian noise to the produced motion plan, and use a forward model to predict where the robot would be after executing the perturbed plans. We compute the percentage of the motion plans, which will cause a collision with obstacles, and then adjust the speed correspondingly.
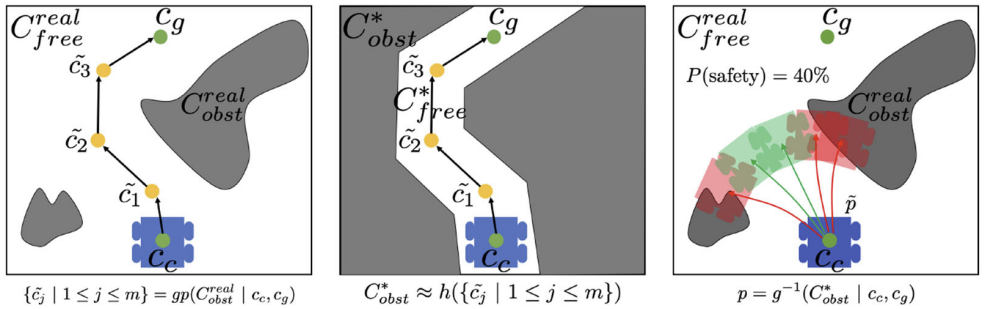
Hallucinated Learning and Sober Deployment (HLSD)
One shortcoming of LfH is the requirement of a relatively fine-resolution global path for runtime hallucination, which may not be available in all navigation systems. The inspiration of HLSD is that not every obstacle in the most constrained obstacle set is required to make a motion plan optimal. One can safely drop many of them and still assure the plan is optimal. Therefore, HLSD identifies a minimal obstacle set, samples in addition to this minimal set to generalize to real-world obstacle configurations, learns the motion planner using the sampled hallucinated obstacles, and then deploys without runtime hallucination. Although a minimal obstacle set to make a motion plan collected in open space optimal is not unique, we empirically show that using a representative minimal obstacle set (d) is sufficient to achieve good navigation performance.
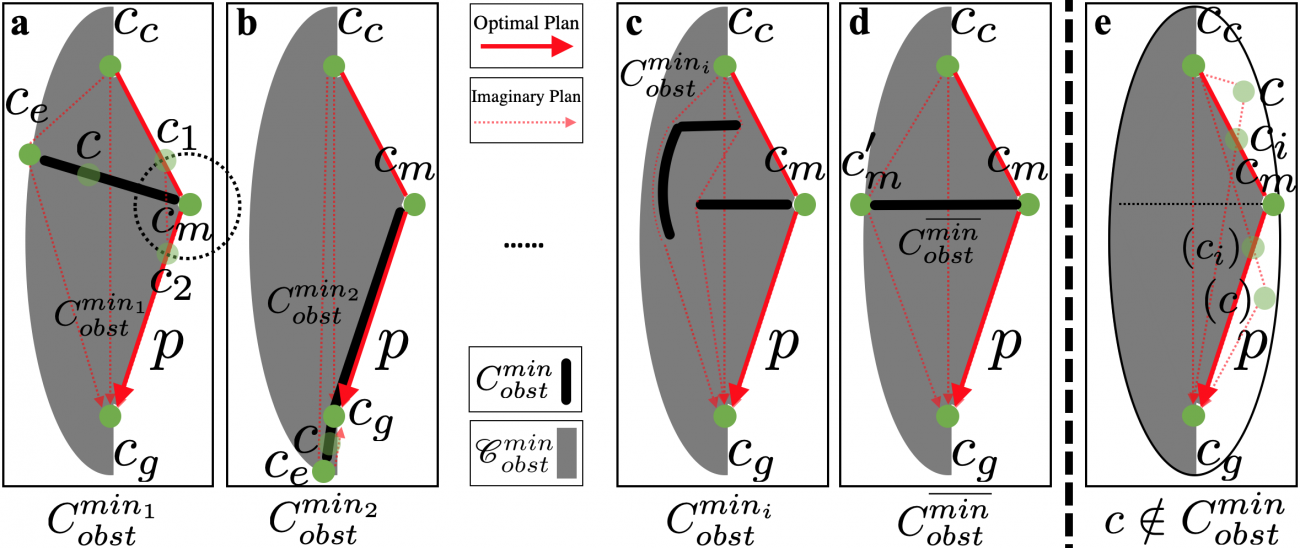
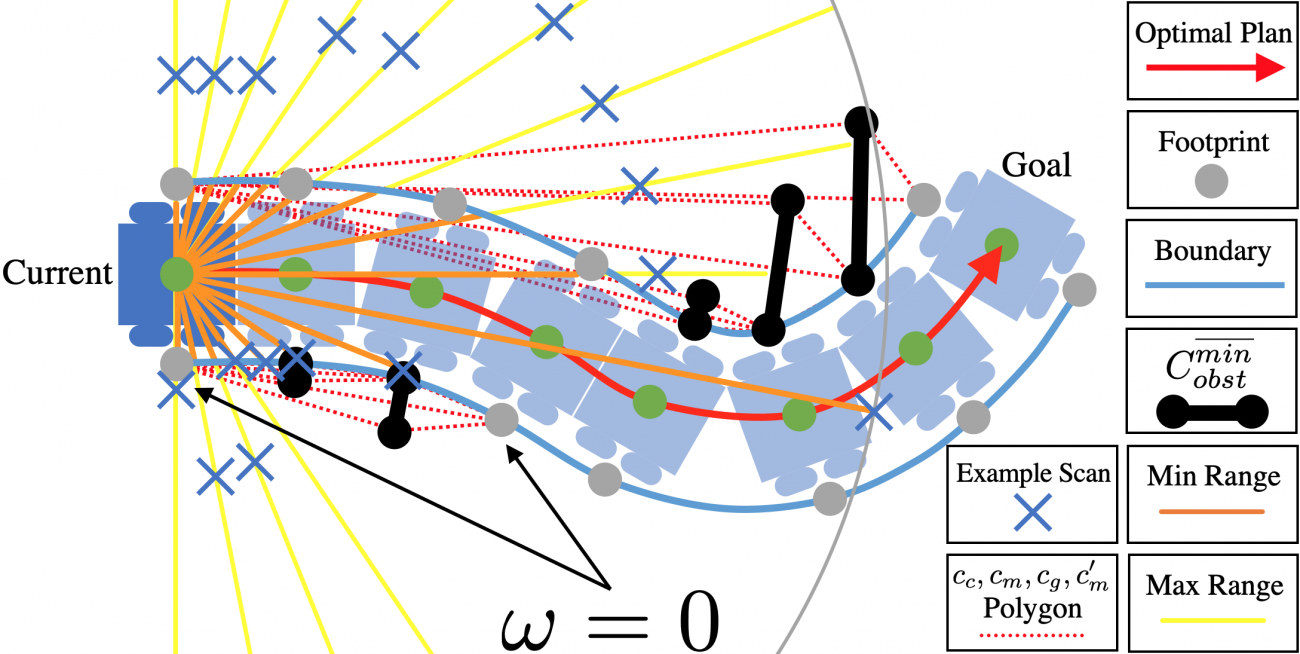
Another advantage of HLSD is being able to account for uncertainty during training, instead of during deployment as in the most constrained case. We bias the sampling (blue x's) to create obstacles in addition to the minimal obstacle set based on the speed of the motion plan collected in open space. For example, for slower motions, we bias the sampled obstacles toward close-by configurations, while for faster motions, the obstacles are expected and thus sampled to be farther away from the robot.
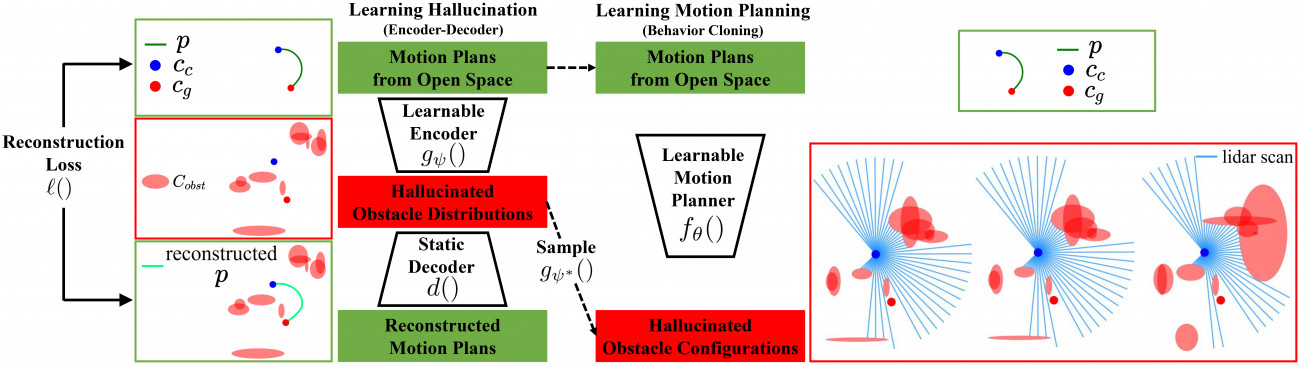
Learning from Learned Hallucination (LfLH)
While hand-crafting the most constrained and a minimal obstacle set may be straightforward for 2D ground robots with a relatively short planning horizon, for faster and higher Degree-of-Freedom mobile robots, e.g., drones, designing such hallucination functions are not easy. To address this issue, LfLH utilizes an encoder-decoder structure to learn a latent space of obstacle distributions, from which many obstacles can be sampled and make the motion plan collected in open space optimal. To be specific, we use a static differentiable optimization-based motion planner as the decoder and learn the parameters for the encoder.
References
- X. Xiao, B. Liu, G. Warnell, and P. Stone, "Toward agile maneuvers in highly constrained spaces: Learning from hallucination," IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 1503-1510, 2021.
- X. Xiao, B. Liu, and P. Stone, "Agile robot navigation through hallucinated learning and sober deployment," in 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021.
- Z. Wang, X. Xiao, A. Nettekoven, K. Umasankar, A. Singh, S. Bommakanti, U. Topcu, and P. Stone, "From Agile Ground to Aerial Navigation: Learning from Learned Hallucination," under review, 2021.
Acknowledgments
This work has taken place in the Learning Agents Research Group (LARG) at the Artificial Intelligence Laboratory, The University of Texas at Austin. LARG research is supported in part by grants from the National Science Foundation (CPS-1739964, IIS-1724157, NRI-1925082), the Office of Naval Research (N00014-18-2243), Future of Life Institute (RFP2-000), Army Research Office (W911NF-19-2-0333), DARPA, Lockheed Martin, General Motors, and Bosch. The views and conclusions contained in this document are those of the authors alone. Peter Stone serves as the Executive Director of Sony AI America and receives financial compensation for this work. The terms of this arrangement have been reviewed and approved by the University of Texas at Austin in accordance with its policy on objectivity in research.
Citations
Learning from Hallucination (LfH)
@article{xiao2021toward,
title={Toward agile maneuvers in highly constrained spaces: Learning from hallucination},
author={Xiao, Xuesu and Liu, Bo and Warnell, Garrett and Stone, Peter},
journal={IEEE Robotics and Automation Letters},
volume={6},
number={2},
pages={1503--1510},
year={2021},
publisher={IEEE}
}
Hallucinated Learning and Sober Deployment (HLSD)
@inproceedings{xiao2021agile,
title={Agile Robot Navigation through Hallucinated Learning and Sober Deployment},
author={Xiao, Xuesu and Liu, Bo and Stone, Peter},
booktitle = {2021 IEEE International Conference on Robotics and Automation (ICRA)},
year={2021},
organization = {IEEE}
}
Learning from Learned Hallucination (LfLH)
@article{wangagile,
title={From Agile Ground to Aerial Navigation: Learning from Learned Hallucination},
author={Wang, Zizhao and Xiao, Xuesu and Nettekoven, Alexander J and Umasankar, Kadhiravan and Singh, Anika and Bommakanti, Sriram and Topcu, Ufuk and Stone, Peter}
}
Contact
For questions, please contact:
Dr. Xuesu Xiao Department of Computer Science
The University of Texas at Austin
2317 Speedway, Austin, Texas 78712-1757 USA
+1 (512) 471-9765
xiao@cs.utexas.edu
https://www.cs.utexas.edu/~xiao/