IFML research collaborations power next generation of multimodal AI with OpenCLIP and DataComp
OpenCLIP, the main text/image encoder in Stable Diffusion, is in the top 1% of all Python packages and has more than 50,000 git clones per day. DataComp, is the first rigorous benchmark for advancing multimodal dataset creation.

A revolution in multimodal AI.
Multimodal datasets combine images and text captions, enabling image understanding, image captioning, and generative AI models. They are a critical component in recent breakthroughs such as Stable Diffusion, CLIP and GPT-4, yet their design does not receive the same research attention as model architectures or training algorithms. OpenAI’s CLIP model was the first building block for connecting images and text, which led to the first computer vision model that could be used reliably for image classification and retrieval. Since its release, CLIP has consistently ranked as one of the five most downloaded models on HuggingFace.
Figure 1: Text prompt generated image in Stable Diffusion
Building on CLIP, industry and university labs (OpenAI, Google, Stability, among others) created a new generation of text-guided image classification models such as DALL-E and Stable Diffusion, the latter of which became one of the most quickly adopted Github repositories. Moreover, DeepMind integrated CLIP-like models with large language models (LLMs) to build Flamingo, the first vision language model that enabled chatbot-like in-context learning with images.
IFML lays the foundations for multimodal AI.
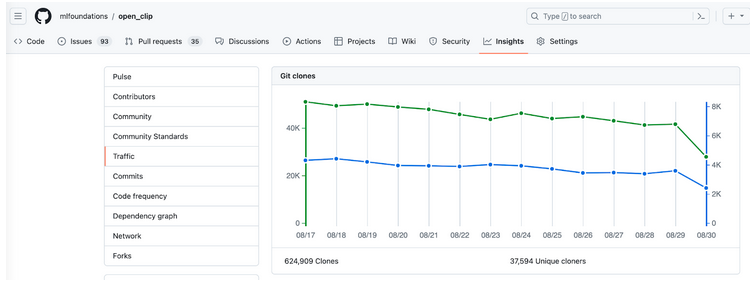
IFML researchers have been at the core of this multimodal revolution in AI. For instance, IFML senior personnel Ludwig Schmidt (University of Washington) and his group developed OpenCLIP, the most widely used open implementation of CLIP models. OpenCLIP has more than 6,000 stars on GitHub, is cloned around 50,000 times per day, and has become one of the top 1% of all Python packages.
In addition, OpenCLIP has become the template for multiple proprietary CLIP implementations at companies and in early 2023, OpenCLIP surpassed the best models released by OpenAI. Finally, OpenCLIP has become the language guidance model in both Stable Diffusion 2 and Stable Diffusion XL.
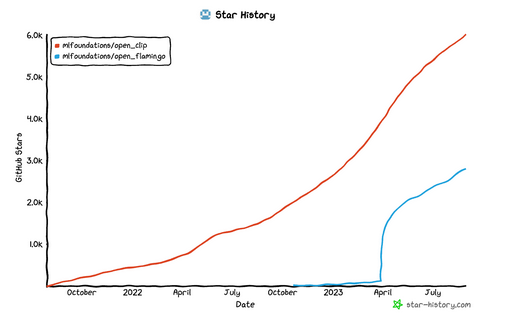
Schmidt’s group also introduced OpenFlamingo, an open source implementation of DeepMind’s Flamingo model. Together, the two repositories have almost 10,000 GitHub stars and are quickly growing:
Multimodal datasets.
Beyond the modeling code, Ludwig Schmidt and his group are also core members of the LAION collaboration and contributed to the LAION-5B dataset in leading roles. LAION-5B was the first public image-text dataset that surpassed one billion examples and enabled training state-of-the-art multimodal models. For instance, both Stable Diffusion and the OpenCLIP models are trained on LAION-5B. The project received an Outstanding Paper Award in the datasets & benchmarks track of NeurIPS 2022, and the LAION-5B dataset has become one of the most widely used datasets for training multimodal models.
In addition to creating widely used algorithms, codebases and datasets, IFML has improved our understanding of CLIP models and large image-text datasets. In particular, Schmidt’s students studied accuracy-vs-robustness trade-offs that emerge when adapting CLIP models to specific downstream tasks, and introduced an improved fine-tuning method that ameliorates these trade-offs. The resulting publication was a best paper finalist at CVPR 2022. Research from IFML co-director Alex Dimakis’ group showed how to make CLIP robust and solve inverse problems in very noisy or maliciously corrupted images. This research has been published in NeurIPS 2021 and is the state of the art in robust multimodal AI.
IFML PIs Dimakis, Oh, and Schmidt have recently collaborated across UT and UW to launch the DataComp project. The goal of DataComp is to better understand how to curate datasets for training foundation models. To this end, the PIs assembled a large collaboration involving more than 30 researchers from industry and academia and created DataComp, the first rigorous benchmark for creating multimodal datasets. The DataComp testbed enables researchers in both academia and industry to investigate new methods for curating training sets for multimodal foundation models.
The testbed itself is centered around a new candidate pool of 12.8 billion image-text pairs from Common Crawl. Participants in the benchmark design new filtering techniques or curate new data sources and then evaluate their new dataset by running a standardized CLIP training code and testing the resulting model on 38 downstream test sets. Our benchmark consists of multiple compute scales spanning four orders of magnitude, which enables the study of scaling trends and makes the benchmark accessible to researchers with varying resources.
Our baseline experiments show that the DataComp workflow leads to better training sets. In particular, our best baseline, DataComp-1B, enables training a CLIP ViT-L/14 from scratch to 79.2% zero-shot accuracy on ImageNet, outperforming OpenAI's CLIP ViT-L/14 by 3.7 percentage points while using the same training procedure and compute.
Universities play a key role in the AI revolution.
The three pillars of AI are Compute, Data, and Algorithms. Universities and academic peer-reviewed research are critical in the ever-evolving AI revolution, substantively contributing to all three pillars. Peer-reviewed research, public datasets, and available models are enabling security, safety and robustness, while democratizing innovation, in a way that no closed or centralized system can.. Further, academic research creates new algorithms and curated datasets that fuel the AI industry ecosystem and keep it competitive, trustworthy and robust. Academic peer-reviewing is the best way we know for making robust scientific progress. Industry is greatly contributing to the peer-reviewing ecosystem, but it is still primarily maintained by volunteers from Universities. Concretely, numerous large companies (like Meta, Amazon and Apple) and startups (like Anthropic, Stability, Runway, SparkCognition) are using models, algorithms and datasets created by IFML, published with licenses that allow research and commercial use. Finally, universities are the primary driver for workforce development: training the AI experts who know how to curate, evaluate, train and secure large AI models from malicious uses.